Launched in August 2025, the AI-Assisted Review Framework (ARF) streamlines manual, multi-level
product reviews into a scalable, expert-verified workflow. By combining autonomous assessments,
real-time compliance monitoring, and AI-assisted reviewer tools, ARF improves consistency and
efficiency across high-volume product categories.
IMPACT
4M → 25MScaled Annual Review Throughput
60%Reduction in Multi-Level Human Reviews
>99%Accuracy Maintained with Minimal Overrides
70%+Saved Time Reinvested in Training & AI Refinement
15–20%Improved Expert Reviewer Efficiency
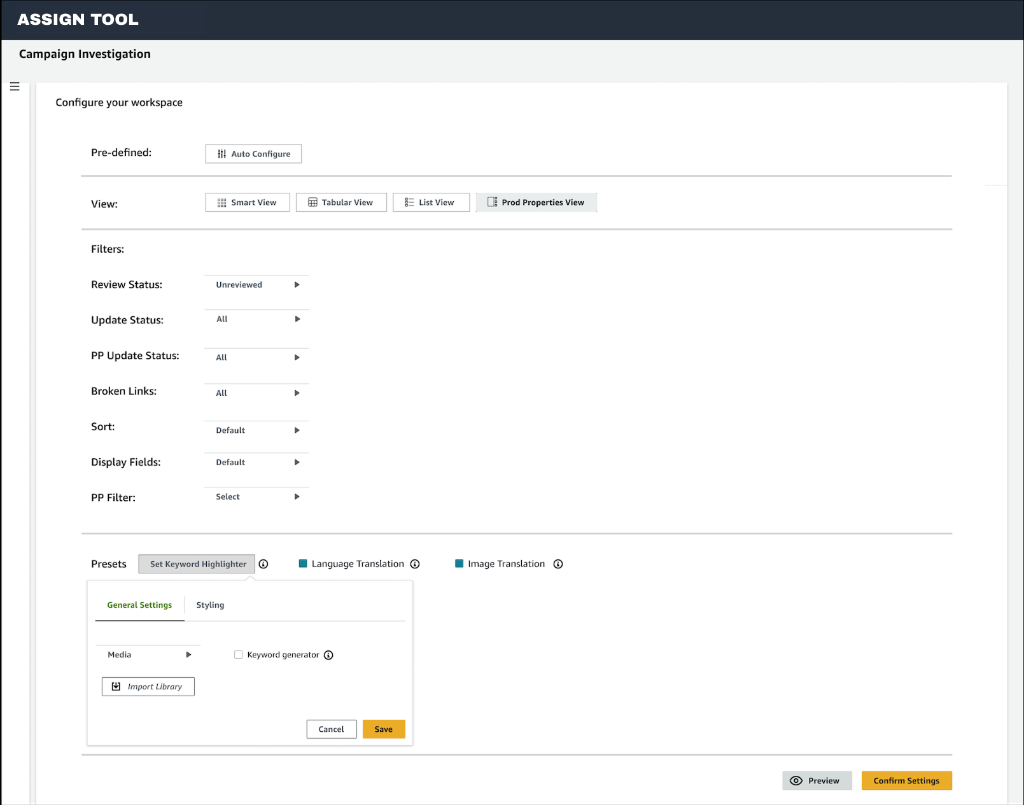
Timeline, Role & Scope
Timeline
August 2025 - Launched the AI-Assisted Review Framework (ARF), transforming product
evaluation workflows across high-volume categories.
Role
Lead UX Designer, Experience Strategy, Human-AI Interaction, UX/UI
Scope & Responsibility
Defined the end-to-end reviewer experience strategy, aligning AI autonomy with human
expertise to enable a scalable, trustworthy human-in-the-loop review system.
Defining the Reviewer
Experience Strategy
Designed AI-assisted reviewer interfaces to support complex decision-making with
transparency and control.
Partnered with Applied Scientists and PMs to define human-in-the-loop workflows and
guideline compliance mechanisms.
Created data-driven dashboards for review monitoring, performance visibility, and feedback
loops.
Led the transition from manual, multi-level reviews to AI-assisted verification, improving
trust, adoption, and operational efficiency.
Outcome
A Unified, AI-First Framework
ARF has transformed the way product reviews are conducted, establishing a unified, AI-first
framework that scales across high-volume categories such as Clothing, Grocery, and Media. It
redefines human–AI collaboration by combining speed, accuracy, and trust, and sets the
foundation for an organization-wide intelligent review ecosystem.
Case Study — Deep Dive
Background
To ground the solution in real operational behavior, we conducted 1:1 interviews with Operational
Leads and Quality Operators working within a large-scale review platform. The focus was on
understanding day-to-day responsibilities, pain points, workarounds, and decision paths involved
in assigning classification outcomes to product records.
Discovery Goals
Identify strengths and friction points in the human review experience.
Understand how operators supplement the core system with internal or external tools.
Examine workflow variance by tenure (novice vs. experienced), operators at different
levels (1 /
2 / 3).
Methodology
ContextLive production operations environment
Participants4 associates (Leads, L1/L2/L3 operators, and
novice)
ApproachEnd-to-end walkthroughs, tool-usage
inventories, gap analysis
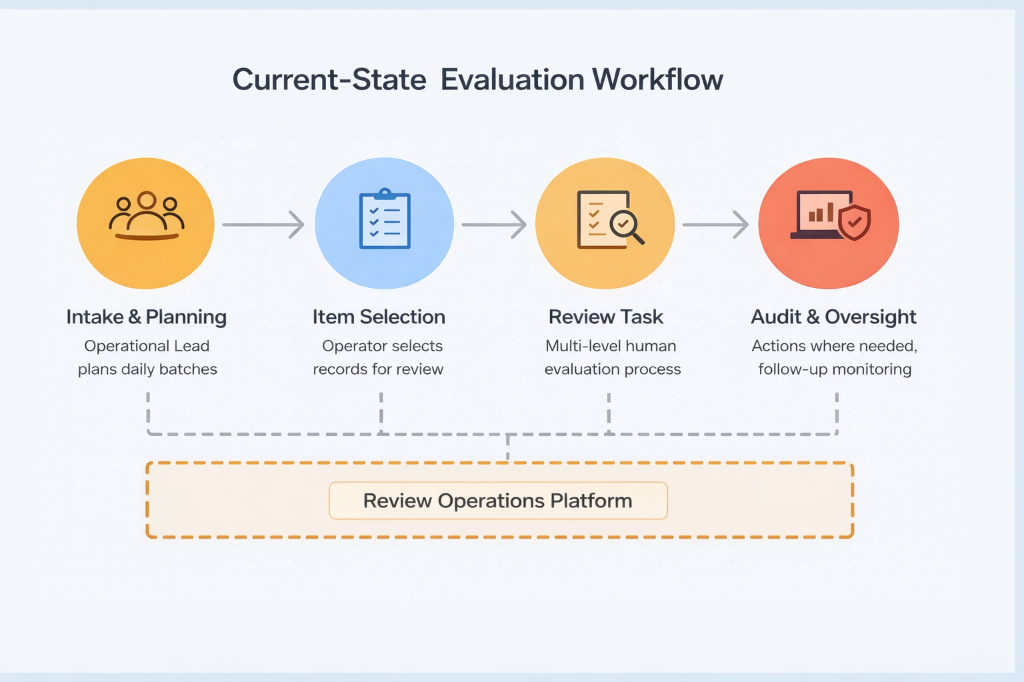
Process Overview (Current State)
Workload Planning
Operational Leads create daily evaluation batches based on operator availability and
active workload.
Multi-Level Evaluation Model
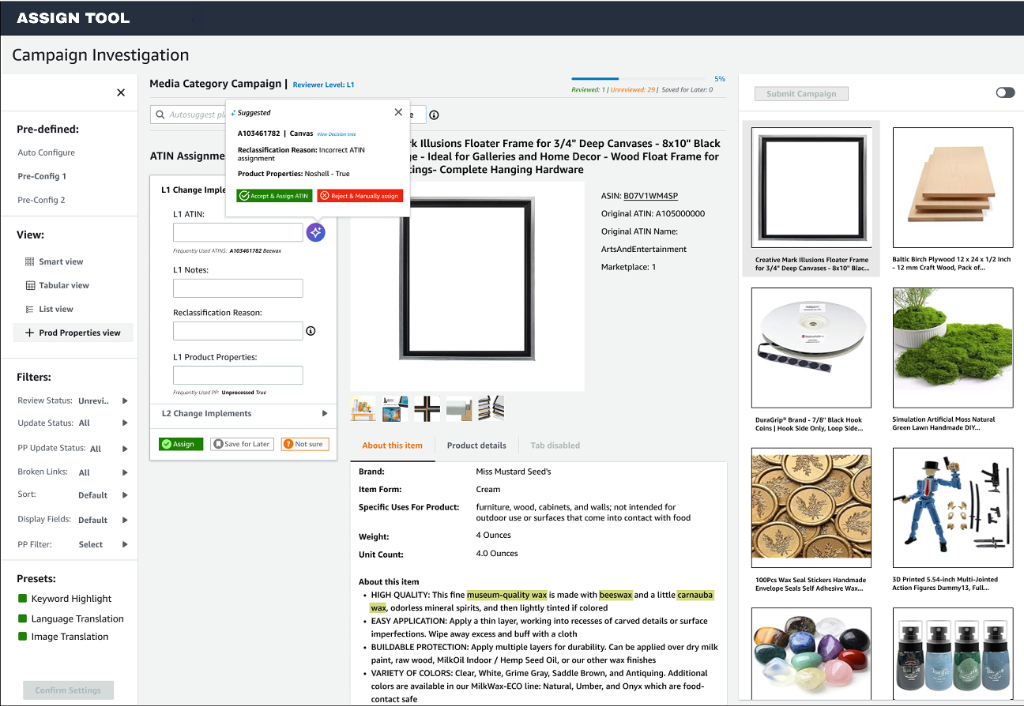
Level 1 Operator:
Initial review, classification assignment, and notes.
Level 2 Operator:
Validation and overrides, including reclassified records.
Clear visibility into operator availability and workload.
Efficient generation of review batches.
Ability to monitor progress and intervene when needed.
Quality Operators
Strong mental models developed through long-term system use.
Flexibility to augment the core platform with personal efficiency aids.
Access to subject-matter experts and distributed knowledge references for
clarification and edge cases.
What Hurts
Swivel-chair overhead
Both Operational Leads and Quality Operators rely on frequent tool switching, manual
tracking, and repetitive setup, increasing cognitive load and reducing throughput.
Manual capacity planning
Daily workload planning is mechanical and time-intensive, often requiring ~1 hour each
morning to balance capacity against incoming review volume.
Reliance on unsanctioned extensions
Third-party add-ons compensate for missing core capabilities (e.g., highlighting,
translation, cross-market context) but introduce:
Compliance risk due to lack of formal approval,
Low traceability, with no visibility into how decisions were reached,
Fragility, as updates or security blocks can disrupt workflows.
Fragmented knowledge landscape
Edge cases and historical decisions are scattered across multiple systems and documents,
leading to repeated research and inconsistent application.
Language and image interpretation gaps
External translation and image-recognition tools are frequently used, but accuracy and
context loss introduce ambiguity, especially in high-risk classifications.
High onboarding burden
New operators take months to reach the efficiency of tenured peers due to tool sprawl,
cognitive overhead, and limited in-product guidance.
Outcome inconsistency
In the absence of clear, embedded guidance, final classification decisions often rely on
individual judgment, increasing variability across operators.
Experienced operators use heuristics and pattern recognition
Reviewer Journey Snapshots
Note: These personas represent observed behavioral patterns from user research. Terminology and
tooling have been generalized to preserve confidentiality.
Novice Operator (Level 1)
~3–7 minutes per item
Follows a full, methodical review flow with limited shortcuts.
Relies heavily on internal reference materials, external lookups, and peer guidance
to build confidence.
Frequently uses translation support and defers ambiguous cases for later review.
Experienced Operator (Level 1 / 2)
~45 seconds–2 minutes per item
Develops personalized workflows to speed up routine reviews.
Uses keyword cues and pattern recognition to bias scanning toward likely
classifications.
Leverages cross-market context and translation support when reviewing non-English
content.
Dives deeper only for edge cases (e.g., detailed specifications, packaging,
ingredients).
Completes reviews in batches once confident.
Senior Operator (Level 2 / 3)
Quality Assurance
Focus
Reviews and validates changes made by Level 1 operators; may override when needed.
Resolves disagreements through discussion and shared decision-making.
Performs additional verification when classification outcomes impact downstream
compliance.
Acts as a final quality checkpoint rather than a primary reviewer.
Key Insight
As operator experience increases, decision speed improves through heuristics, but
consistency depends on access to context, guidance, and explainability rather than memory
alone.
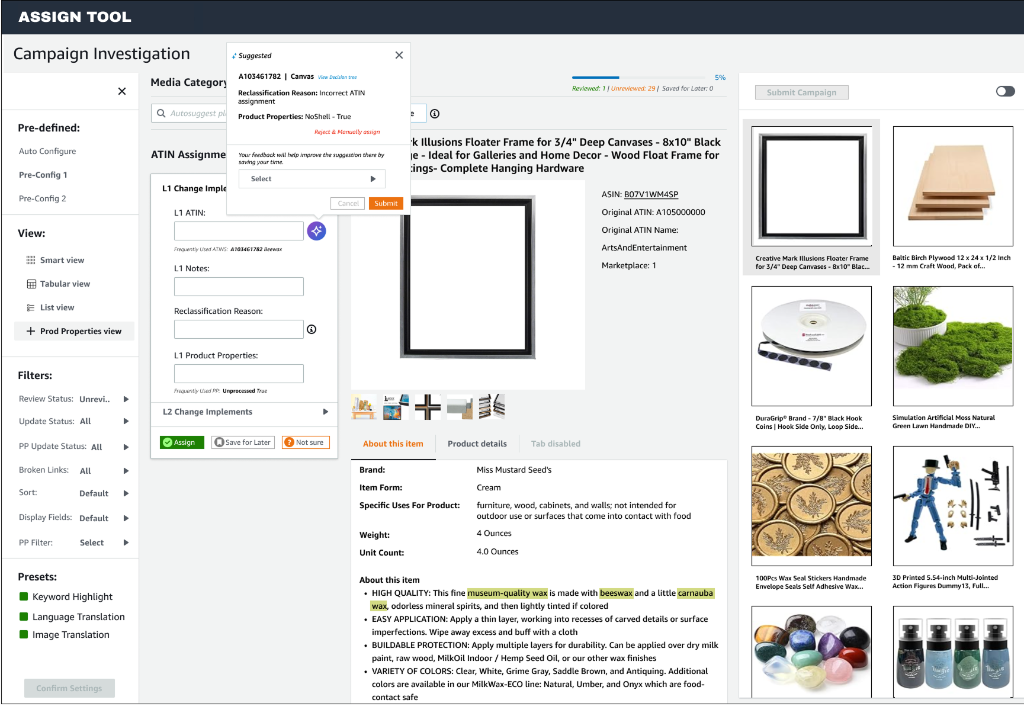
Add-Ons & Scripts (Observed Workarounds)
During research, operators frequently supplemented the core review workflow with third-party
browser tools to compensate for missing or inefficient capabilities. While these tools improved
speed and task completion, they also introduced risks around consistency, traceability, and
long-term scalability.
This section highlights observed patterns, not prescribed workflows.
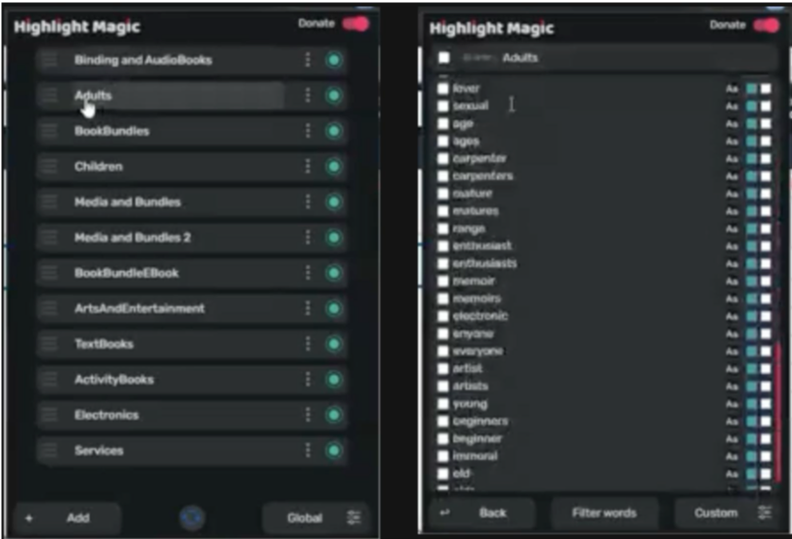
Keyword Highlighting Extensions
What operators used them for
Rapid visual scanning of long product descriptions
Emphasizing keywords tied to classification heuristics
Sharing personal keyword sets to speed up repeat reviews
Why they helped
Reduced time spent reading dense content
Supported pattern recognition for experienced operators
Improved throughput in high-volume scenarios
Where they fall short
Operate outside the core workflow with no audit trail
Decisions influenced by highlights are not traceable
Fragile dependency on browser updates and permissions
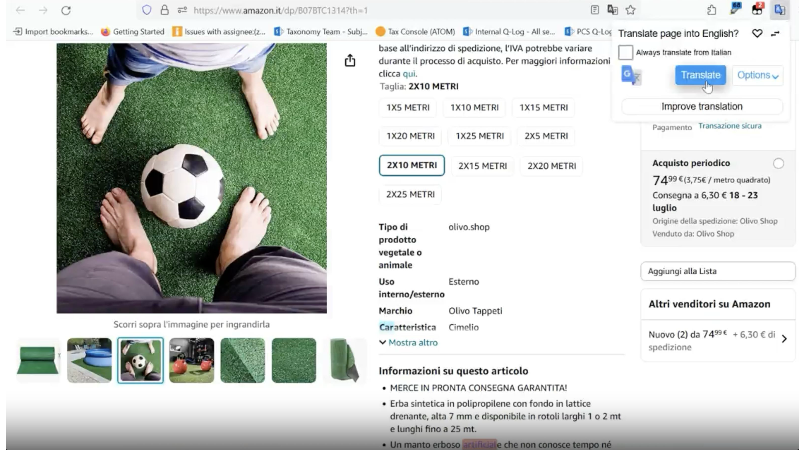
Script-Based Translation & Marketplace Switching
What operators used them for
Reviewing products across multiple locales and languages
Switching regional storefronts to gather context
Reducing manual effort during cross-market reviews
Why they helped
Lowered friction in multilingual review scenarios
Enabled faster access to regional product context
Reduced context switching across tabs and tools
Where they fall short
Translation accuracy varies by category and language
Security blocks or policy changes can stall reviews
Inconsistent behavior across markets
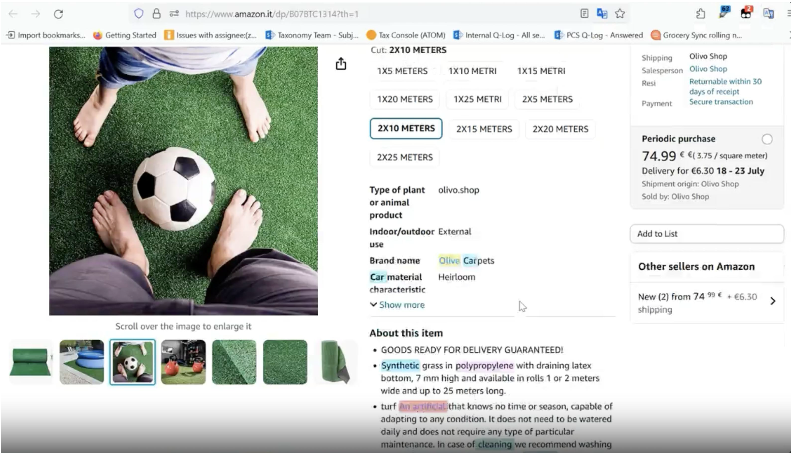
Image-Based Text Translation (On-Image OCR)
What operators used them for
Interpreting text embedded directly in product images
Reviewing packaging, labels, and instructions in foreign languages
Filling gaps where text descriptions were insufficient
Why they helped
Increased throughput for image-heavy listings
Reduced manual transcription or guesswork
Where they fall short
OCR and translation errors introduce ambiguity
Limited clarity between initial and secondary review outcomes
Key Insight
These workarounds highlight a recurring theme: operators optimize for speed and confidence,
even when tooling gaps force them outside the primary system. At scale, this creates risk —
not because of human behavior, but because critical decision support is fragmented and
ungoverned.
This insight directly informed the need for native, explainable, and traceable AI-assisted
review capabilities within ARF.
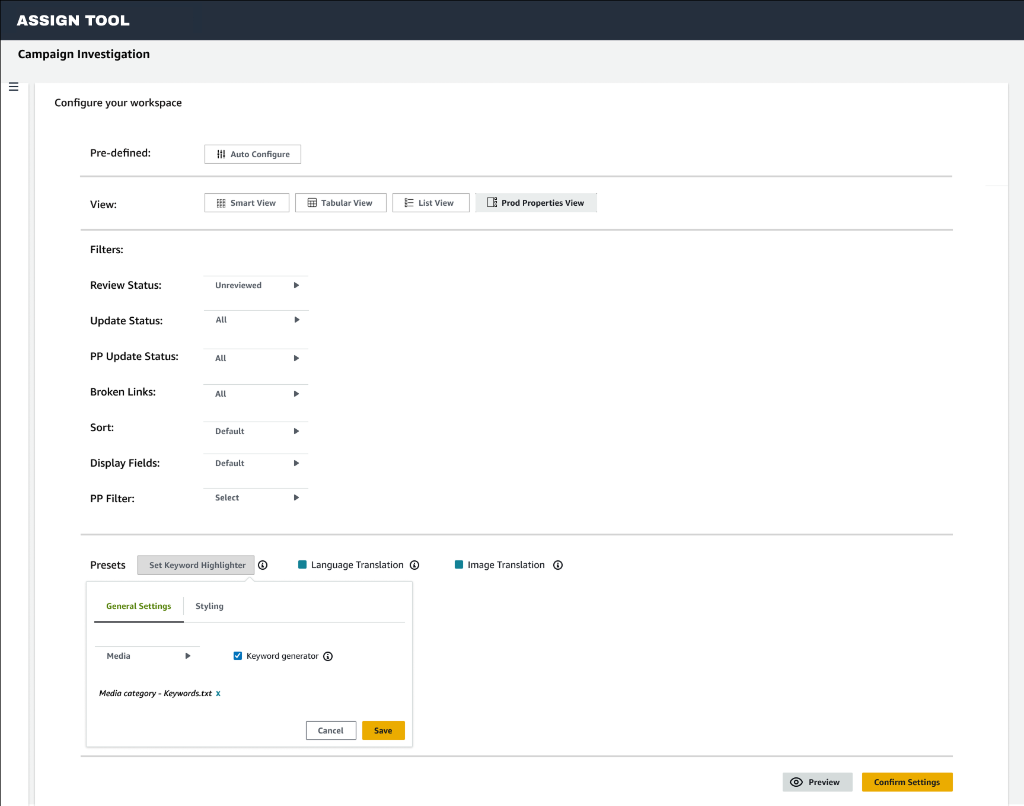
Opportunities
Native Guidance
Embed guidance directly into the workflow so operators understand why, not just what.
In-product cues & decision paths
Persistent preferences
End-to-end traceability
First-Class Intelligence
Treat translation and image understanding as core capabilities.
Built-in OCR & confidence scores
Marketplace-aware logic
Capacity Visibility
Shift from manual load balancing to system-assisted orchestration.
Auto-suggested sizing
Live progress & risk tracking
Accelerated Upskilling
Reduce tribal knowledge by making expertise visible and transferable.
Explainable AI overlays
Inline coaching prompts
Strategic Paths Considered
Option 1 — Build a Native, Governed Capability
Recommended
Replace ad-hoc extensions with a unified, auditable platform that:
Captures decision signals and supports traceability
Centralizes knowledge with contextual retrieval
Integrates language, image, and marketplace intelligence
Automates capacity-aware planning
Reduces swivel-chair effort while increasing throughput
Outcome: Scalable speed with trust, consistency, and governance.
Option 2 — Enforce No-Add-On Compliance
Remove external tools without addressing core gaps.
Risk:
Slower review cadence
Higher cognitive load
Increased ambiguity in multi-market scenarios
Greater inconsistency across operators
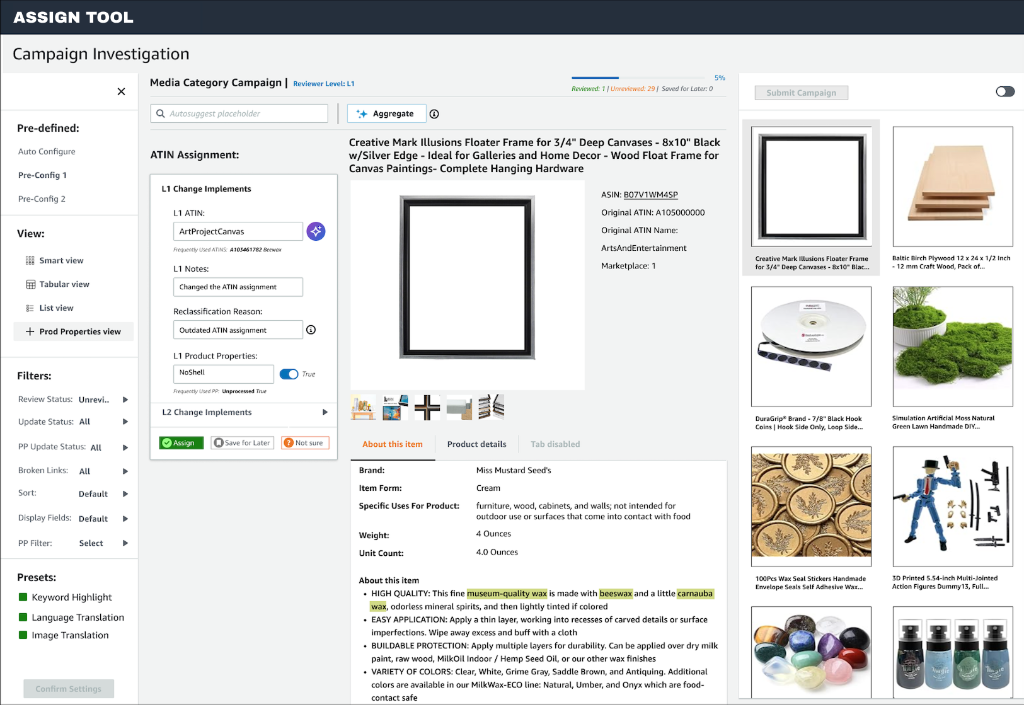
Design
Usability Testing — Outcomes
Conducted usability testing with six operators across multiple product categories using interactive
prototypes to evaluate usability, transparency, and adoption readiness.
What Worked
Strong adoption: 83% of participants (5 of 6) recognized AI’s potential
to significantly improve productivity.
Transparency: Visible decision trees explaining AI recommendations
increased trust.
Adaptability: Despite initial skepticism, operators adjusted quickly to
the hybrid human–AI workflow.
Familiarity: Blending existing review patterns with product detail page
elements eased the transition.
What to Improve
Change management: Job-security concerns related to AI adoption.
Trust calibration: Skepticism about AI matching human judgment in edge
cases.
Workflow adoption: Initial resistance to AI-assisted decision-making.
Learning curve: New interface elements required clearer onboarding and
guidance.
Key Learning
Adoption success depends more on human factors—clear explainability (XAI), visible control, and
effective change management—than on model quality alone.
Phase 1 Launch — 2025
What We Launched
Background automated reviews with single-level human verification replacing multi-level
workflows.
Complex cases routed to experts with AI assistance, enabling smaller and faster campaigns.
Automatic guideline updates with continuous performance monitoring.
Results to Date
63%
Reduction in secondary and tertiary reviews
3.78%
Of reviews required changes
74%
Of saved time reinvested in training and upskilling
17%
Net capacity gain for expert operators
4M → 25M
Throughput (reviews per year)
Expansion
September 2025Expanded to Grocery, Medical, and Media
categories
Q1 2026 (target)Standalone, unified AI-assisted review system across
categories
What This Work Established
ARF established a new operating model for high-volume decision systems—one where AI accelerates
scale, but humans retain authority, accountability, and judgment. The work reframed review from a
manual throughput problem into a design challenge centered on trust, explainability, and change
management.
More than a single launch, ARF laid the foundation for future AI-assisted workflows by proving that
transparency, traceability, and human oversight are prerequisites for sustainable automation, not
optional enhancements.